Django와 Flutter/React로 구축하는 AI 기반 의료 CDSS
Django와 Flutter/React로 구축하는 AI 기반 의료 CDSS: 개발 여정 및 아키텍처 탐구 (CT & Multi-omics)
안녕하세요! 오늘은 Python Django, Celery, Flutter, React 등 다양한 기술 스택을 활용하여 AI 기반 의료 임상 의사 결정 지원 시스템(CDSS)을 구축하는 과정과 그 과정에서 겪었던 문제 해결 경험을 공유하고자 합니다. 이 글은 CT 영상 분석과 Multi-omics 데이터 분석 기능을 포함하는 시스템 개발의 전체적인 흐름과 기술적 선택, 그리고 트러블슈팅 과정을 다룹니다. (예상 읽기 시간: 10-12분)
1. 프로젝트 목표 및 개요
저희 프로젝트의 목표는 의료진이 환자의 CT 영상 데이터와 유전체, 단백체 등 다양한 Multi-omics 데이터를 기반으로 더 정확하고 신속하게 진단을 내릴 수 있도록 보조하는 AI 기반 CDSS를 개발하는 것입니다. 사용자는 모바일 앱(Flutter) 또는 웹(React)을 통해 환자 데이터를 업로드하고 분석을 요청하며, 시스템은 백엔드에서 AI 모델을 실행하여 예측 결과, 관련 시각 자료, PDF 보고서 및 AI 기반 해석을 제공합니다.
2. 시스템 아키텍처 설계
안정적이고 확장 가능한 서비스를 위해 다음과 같은 클라이언트-서버 아키텍처를 채택했습니다.
(1) 백엔드 (Server-Side): Django & Celery 기반
핵심 로직과 데이터 처리, 저장은 모두 서버 측 백엔드에서 이루어집니다.
- 웹 프레임워크 (Django): Python 기반의 강력하고 성숙한 웹 프레임워크인 Django를 사용하여 전체 백엔드 구조를 구축했습니다. 모델(Models), 뷰(Views), 템플릿(Templates)/API, ORM 등 Django의 기능을 적극 활용했습니다. 앱 구조는 기능별(
users,patients,diagnosis,multi_omics)로 분리하여 모듈성을 높였습니다. - API 서버 (Django REST Framework): 프론트엔드(Flutter, React)와의 효율적인 통신을 위해 Django REST Framework(DRF)를 사용하여 RESTful API를 구축했습니다. JWT(JSON Web Token) 기반 인증, API 버전 관리(/api/v1/), 자동 API 문서 생성(drf-spectacular -> Swagger/ReDoc) 등의 기능을 구현했습니다.
- WSGI 서버 (Gunicorn): 실제 서비스 환경에서 Django 애플리케이션을 안정적으로 실행하기 위해 Gunicorn을 WSGI 서버로 사용합니다. 여러 워커 프로세스를 통해 동시 요청을 효율적으로 처리합니다.
- 웹 서버 / 리버스 프록시 (Nginx - 추정): Gunicorn 앞단에서 외부 요청을 받는 역할입니다. 정적 파일/미디어 파일 직접 서빙으로 성능을 높이고, Gunicorn/Django를 외부에 직접 노출시키지 않으며, 필수적인 HTTPS(SSL/TLS) 암호화 처리 및 로드 밸런싱 기능을 담당합니다.
- 데이터베이스 (MySQL - 추정): 사용자, 환자, 분석 요청, 최종 결과 등 모든 정형 데이터는 관계형 데이터베이스인 MySQL에 저장합니다. Django ORM을 통해 상호작용합니다.
- 비동기 작업 처리 (Celery & Redis): AI 모델 추론, PDF 생성 등 시간이 오래 걸리는 작업은 사용자 요청에 대한 응답 시간을 지연시키지 않도록 Celery를 사용하여 백그라운드에서 비동기적으로 처리합니다.
- Redis (메시지 브로커): Django가 Celery에게 작업을 요청할 때, 작업 내용을 담은 메시지를 Redis의 큐에 저장하는 역할입니다.
- Redis (결과 백엔드): Celery 작업의 완료 상태나 간단한 결과를 저장하여 추적할 수 있도록 합니다.
- 파일 저장소 (Filesystem): 사용자가 업로드한 의료 데이터 파일(NIfTI 등)과 시스템이 생성한 결과 파일(Plot 이미지, PDF, 3D HTML 등)은 서버의 파일 시스템(
MEDIA_ROOT)에 저장됩니다. - AI/ML 모델: CT 분석용 PyTorch/MONAI 모델(
.pth)과 Multi-omics 분석용 Scikit-learn 모델(.pkl) 등을 별도 디렉토리(ai_models/)에 저장하고,settings.py에서 경로를 관리하며 Celery Task에서 로드하여 사용합니다. - 기타 유틸리티: PDF 생성(WeasyPrint), 3D 시각화(Plotly, scikit-image), 2D 플롯(Matplotlib), AI 텍스트 생성(Google Gemini API) 등 다양한 Python 라이브러리를 활용합니다.
(2) 프론트엔드 (Client-Side): Flutter & React
사용자가 직접 상호작용하는 인터페이스입니다.
- Flutter 모바일 앱 (
CDSS_MOBILE): iOS 및 Android 사용자에게 네이티브 앱 경험을 제공합니다. 사용자 인증, 데이터 업로드, 분석 요청 제출, 결과 확인(텍스트, 이미지 로드, PDF 뷰어, 3D HTML용 WebView 등) 기능을 구현합니다. 백엔드 API와 통신하기 위해http또는dio패키지를 사용합니다. - React 웹 앱: 웹 브라우저를 통해 데스크톱 등에서 접근할 수 있는 인터페이스를 제공합니다. Flutter 앱과 유사한 기능을 제공하며, 동일한 백엔드 API를 호출합니다.
(3) 전체 데이터 흐름 (예시: CT 분석 요청)
- 사용자가 Flutter/React 앱에서 CT 이미지와 정보를 입력하고 분석 요청.
- 앱이 백엔드 API (
/api/v1/diagnosis/requests/) 호출 (JWT 토큰 포함). - Nginx가 요청을 받아 Gunicorn으로 전달.
- Gunicorn이 Django View 실행.
- Django View는 요청 유효성 검사, 파일 저장(
MEDIA_ROOT),DiagnosisRequest객체 생성 및 DB 저장(Status: PENDING), Celery Task (run_ct_diagnosis_task) 호출 메시지를 Redis에 전송 후, 앱에 “요청 접수됨” 응답 전달. - Celery Worker가 Redis에서 작업 메시지 수신 후
run_ct_diagnosis_task실행 시작. Request 상태를 PROCESSING으로 DB 업데이트. - Task가 파일 로드, 전처리, PyTorch 모델 추론, 결과 분석, Plot 생성/저장, PDF 생성/저장, Gemini 해석 요청/저장 등 수행 (
utils.py함수 활용). - 모든 결과(파일 경로 포함)를
DiagnosisResult객체에 담아 DB에 저장 (update_or_create), Request 상태를 COMPLETED로 업데이트. - Flutter/React 앱은 주기적으로 또는 푸시 알림을 통해 결과 상태 확인 API 호출.
- 완료 상태 확인 후, 결과 조회 API 호출.
- 백엔드 Django View는 DB에서 결과 조회 후 필요한 정보(텍스트, 숫자, 파일 URL 등)를 앱에 전달.
- 앱은 받은 정보와 URL을 이용해 화면에 결과 표시 (이미지/PDF 등은 해당 URL로 서버(Nginx)에 직접 요청하여 로드).
3. 개발 과정 및 트러블슈팅 경험
시스템을 구축하면서 여러 기술적인 문제에 부딪혔고, 이를 해결하는 과정에서 많은 것을 배울 수 있었습니다. 몇 가지 주요 사례를 공유합니다.
- Celery/Gunicorn 서비스 관리:
systemd로 서비스들을 관리하면서, 오류 발생 시sudo journalctl -u <service_name>.service -f -n 100명령어로 실시간 로그와 오류 스택 트레이스를 확인하는 것이 문제 해결의 첫걸음이었습니다. - 데이터베이스 오류 (
IntegrityError,FileNotFoundError등):IntegrityError:NOT NULL제약 조건이 있는 필드에None값을 저장하려 할 때 발생했습니다. AI 해석 함수가 실패 시None을 반환하는 경우, DB 저장을 위해 빈 문자열("")로 처리하거나 모델 필드에null=True를 추가하고 마이그레이션하는 방법으로 해결했습니다.FileNotFoundError: Celery Task에서 입력 파일 경로를 상대 경로로 사용하거나 DB에 경로가 잘못 저장되어 발생했습니다.settings.MEDIA_ROOT와 DB에 저장된 상대 경로를os.path.join으로 조합하여 절대 경로를 사용하고,default_storage.exists()로 파일 존재 여부를 먼저 확인하는 로직을 추가하여 해결했습니다. 근본적으로는 파일 업로드 시점의 경로 저장 로직을 점검하는 것이 중요했습니다.result_obj.save()누락: 모든 결과값을 객체 필드에 할당한 후 최종적으로.save()(또는update_or_create)를 호출해야 DB에 반영된다는 기본적이면서도 중요한 점을 다시 확인했습니다.results_for_db딕셔너리에 모든 값을 담아update_or_create의defaults로 전달하는 방식으로 수정했습니다.
- Python 코드 오류 (
SyntaxError,AttributeError,VariableDoesNotExist):SyntaxError (invalid non-printable character): 코드 복사/붙여넣기 과정에서 눈에 보이지 않는 특수 공백 문자(U+00A0)가 들여쓰기에 포함되어 발생했습니다. 편집기의 특수 문자 표시 기능을 켜서 해당 문자를 찾아 삭제하고 일반 스페이스로 수정하여 해결했습니다.AttributeError: 객체에 존재하지 않는 속성이나 메서드를 호출할 때 발생했습니다. Celery Task 환경에서request객체가HttpRequest가 아님에도build_absolute_uri를 호출하려던 문제,DiagnosisResult객체에 특정 plot 경로 필드가 없는데 접근하려던 문제 등이 있었습니다.getattr()을 사용한 안전한 속성 접근,settings.SITE_URL사용 등으로 해결했습니다.VariableDoesNotExist: Django 템플릿에서 context에 전달되지 않은 변수를 사용하려고 할 때 발생했습니다. PDF 템플릿에서requester변수를 찾지 못했던 경우,tasks.py에서pdf_context를 만들 때request_obj를 전달하고 템플릿에서request_obj.requester로 접근하도록 수정하여 해결했습니다.
- API 및 외부 서비스 연동 오류 (
Gemini NotFound):- Google Gemini API 호출 시
NotFound오류가 발생했습니다. 로그를 통해 확인 결과, 사용하려던 모델 이름(gemini-pro)이 API 버전 또는 기능(generateContent)과 호환되지 않는 문제였습니다. 사용 가능한 모델 이름(gemini-1.5-pro-latest)으로 변경하여 해결했습니다. API 키 권한 문제도 유사한 오류를 유발할 수 있습니다.
- Google Gemini API 호출 시
- 프론트엔드-백엔드 연동 문제 (
ERR_CLEARTEXT_NOT_PERMITTED):- 안드로이드 앱에서 3D 시각화 HTML 파일 등 백엔드의 리소스를 로드할 때 이 오류가 발생했습니다. 원인은 안드로이드 최신 버전의 보안 정책상 암호화되지 않은 HTTP 통신이 기본적으로 차단되기 때문입니다.
- 근본적인 해결책은 백엔드 서버(Nginx)에 SSL/TLS 인증서를 설치하여 HTTPS 통신을 활성화하고, Django
settings.py의SITE_URL과 Flutter/React 앱의 API 호출 주소를 모두https://...로 변경하는 것입니다. (이 작업은 도메인 이름이 필요합니다.)
주요 교훈:
- 명확한 아키텍처 설계: 초기 설계 단계에서 각 컴포넌트(Nginx, Gunicorn, Django, Celery, Redis, DB, Frontend)의 역할을 명확히 정의하는 것이 중요합니다.
- 상세한 로깅의 중요성: 특히 비동기 작업(Celery)과 API 연동 시, 각 단계별로 충분한 로그를 남기는 것이 디버깅 시간을 크게 단축시킵니다.
try...except블록에서traceback을 로깅하는 것은 필수입니다. - 비동기 프로세스 이해: Celery Task는 별도의 프로세스에서 실행되므로 웹 요청 컨텍스트(request 객체 등)에 직접 접근할 수 없다는 점을 항상 염두에 두어야 합니다. 필요한 정보는 Task 호출 시 인자로 명시적으로 전달해야 합니다.
- 파일 경로 처리: 서버 내부 경로(
MEDIA_ROOT,STATIC_ROOT)와 웹 URL 경로(MEDIA_URL,STATIC_URL)를 명확히 구분하고, 필요에 따라os.path.join과urllib.parse.urljoin을 올바르게 사용해야 합니다. 백그라운드 작업에서는 절대 경로 사용이 안전합니다. - HTTPS의 필수성: 최신 모바일 앱이나 웹 환경에서는 보안 및 호환성을 위해 백엔드 API 서버에 HTTPS를 적용하는 것이 거의 필수가 되었습니다.
4. 실제 화면
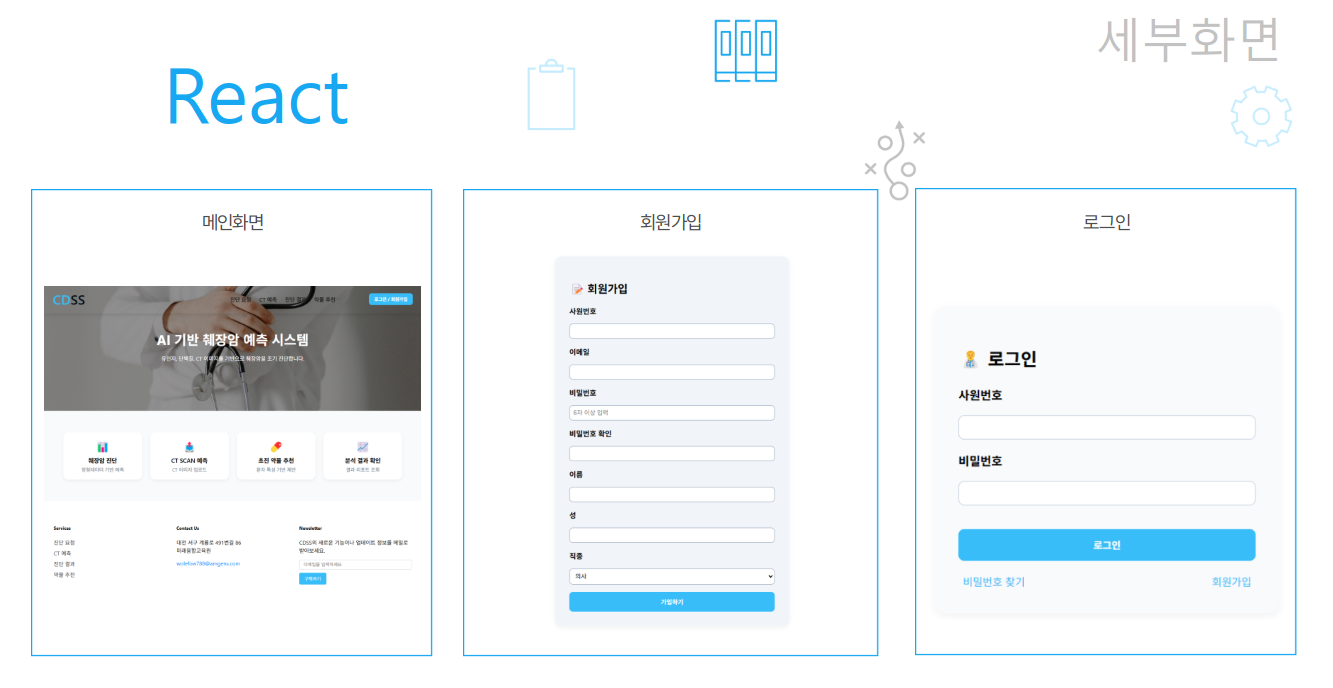
메인 화면
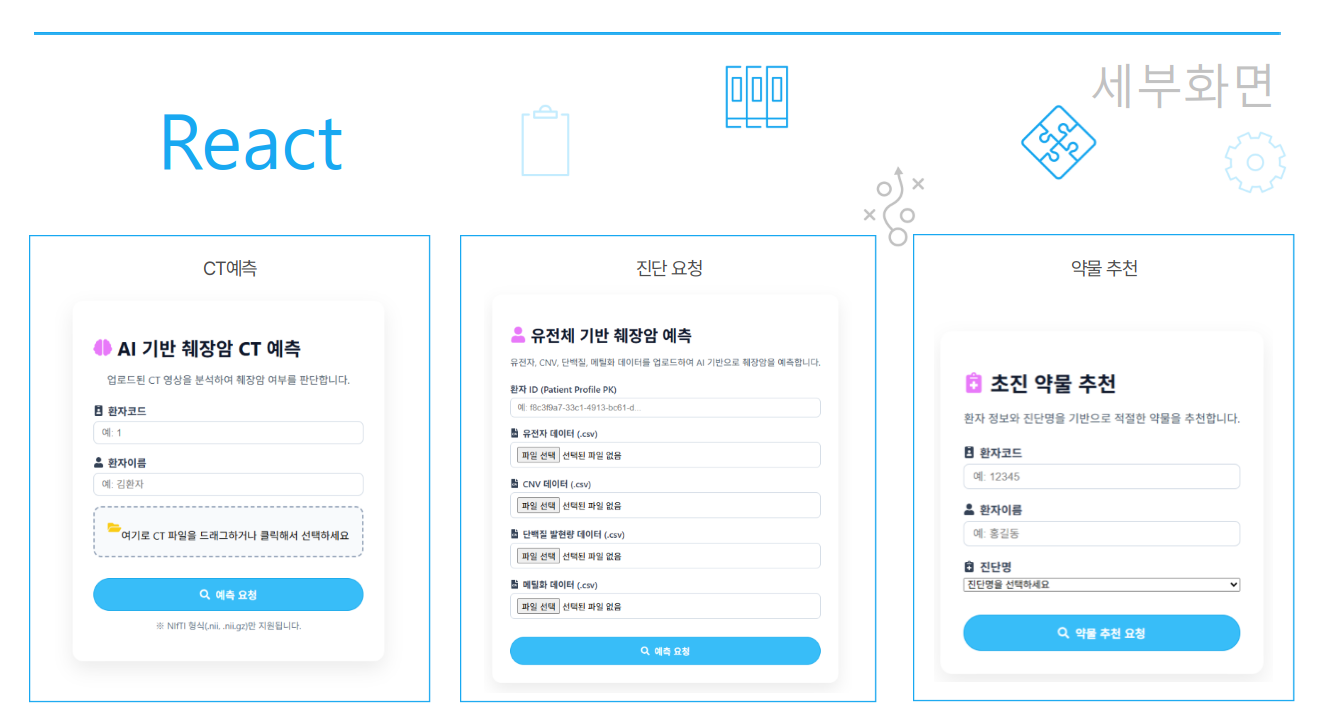
측정 화면
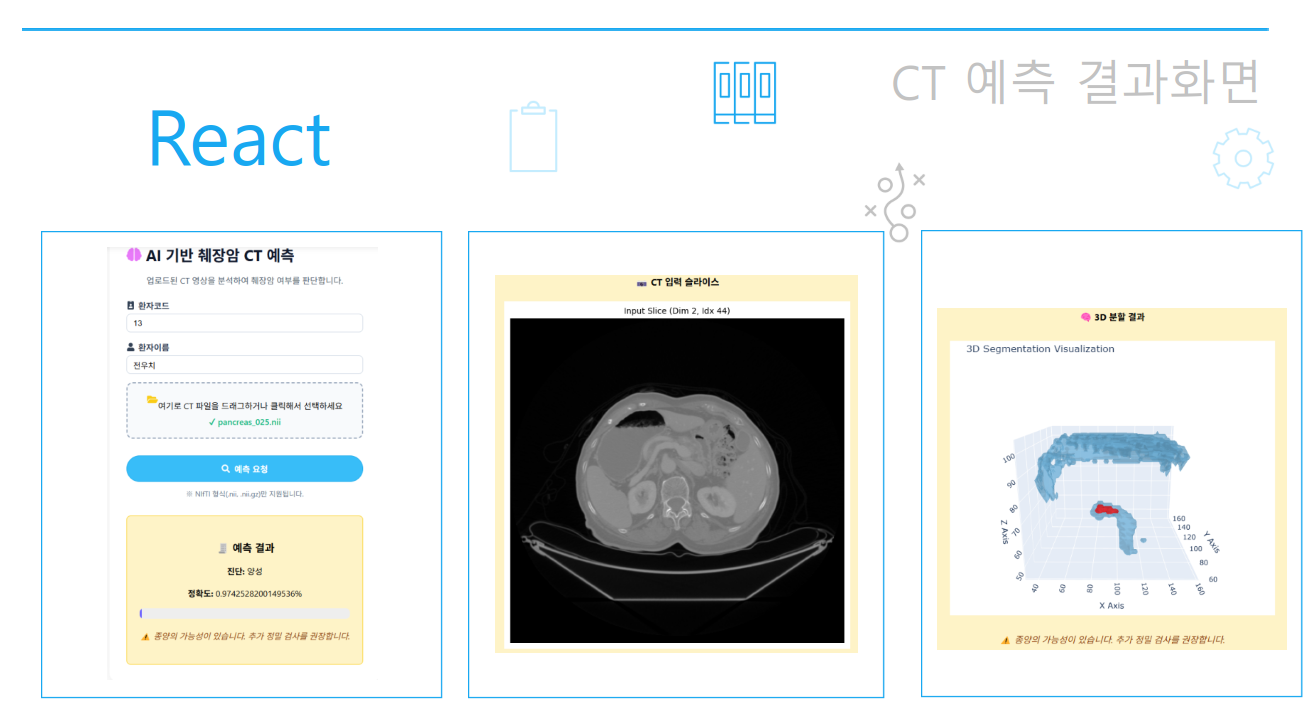
결과 화면
로그인 및 측정 확인
유전체 입력 화면
3D 확인
5. 결론
Django, Celery, Flutter, React 등 다양한 기술을 조합하여 AI 기반 CDSS를 구축하는 과정은 복잡하지만 매우 흥미로운 경험이었습니다. 특히 비동기 처리, API 설계, 프론트엔드-백엔드 연동, 클라우드 배포 환경 설정 등 웹 서비스 개발의 여러 중요 요소들을 깊이 있게 다룰 수 있었습니다. 이 글이 유사한 시스템을 구축하려는 분들께 조금이나마 도움이 되기를 바랍니다.