R의 특징과 자료 구조 - 1 ( 기본 개념 및 설치 과정 )
안녕하세요, 오늘은 R의 특징과 자료구조에 대해 간단히 배워보도록 하겠습니다. 직접 실행해 볼만한 문제도 같이 올려드리니 공부하는데 도움이 되길 바랍니다.
R의 특징과 자료구조
1. R 프로그래밍
아래부턴 구어체로 노트 필기한 것을 정리한 것입니다.
1-1: R 특징
- **In-Memory Computing **(메모리에서 연산을 수행하는 기술) : 빠른 처리 속도 / 단, H/W 메모리 크기에 영향을 받을 수 있음, 병렬처리에 단점이 있다(하나의 메모리에 데이터가 있어야 해서)
- Object-oriented programming : 데이터, 함수, 차트 등 모든 것이 object로 관리
- Package : 최신의 알고리즘 및 방법론이 Package로 제공됨
- Visualization : 분석에 통찰을 부여할 수 있는 그래픽에 대한 강력한 지원
- dynamically typed language : 동적
- 복사가 많이 일어남 : 무결성엔 장점 but 메모리 사용 많아 메모리 정리 잘해야 함(자료구조)
1-2: 프로그래밍 발전 과정
-> 구조적 (if, for)
-> 객체 지향적 (class, 데이터 + 함수) : 함수마다 데이터 타입 지정해야 함 [overroading]
-> 일반화 : Template 으로 대표 타입 지정 : int, float 등으로. (python, R : 포인터라 원본 데이터에 영향 X)
-> 함수적 : (반복문 사용x, 이미 명령어 안에 if, for문이 들어가 있어 벡터화 연산, 멀티코어로 병렬처리 (처리속도 빠름)
1-3: R vs Pysthon
| R | Python | |
|---|---|---|
| 기본 처리 단위 | 벡터 (Vector) | List, Dictionary |
| 데이터 저장 중심 | 벡터 (행), 데이터 프레임 (열) | List |
| 데이터 분류 | 양적/질적 데이터 (양적 변수, 범주화) | 숫자형(int, float), 문자열(str), 불리언(bool) 등 |
| 연산 방법 | 벡터화 연산 지원 | 요소별 연산 |
| 배열 인덱스 | 1부터 시작 | 0부터 시작 |
| 기본 자료구조 | 데이터 프레임(Data Frame) | List, Dictionary |
python에서 statsmodels로 어렵게 되어있는 것을 R로 쉽게 가능
참고) :
- if 조건 연산 / for 벡터화 연산 => R 연산 방법
- 양적((구체적)수치로 지정 가능) 질적(형용사로 표현되어지는 것(높다, 낮다…) (=>범주로 나눠짐, 연속적도 범주로 나눌 수 있음 (100이상 높다 등)) 데이터
- data frame은 pandas, array, matrix는 numpy로 python에서 사용
- R : mode, class로 데이터 타입 확인 가능(숫자냐 문자(캐릭터)인지), 주소이지만 원본 데이터를 건들지 않음 (비교하기 위해 등) -> 따라서 값을 변경하기 위해서는 함수에 리턴 하고 대입해줘야 한다.
2. R의 자료 구조
2.1: Vector
: (배열되어 있는 것을) 데이터를 크기(클러스터)와 방향(딥러닝_내적(유사도))으로 보겠다. => 데이터 프레임에 저장 : 1차원 (동질적) 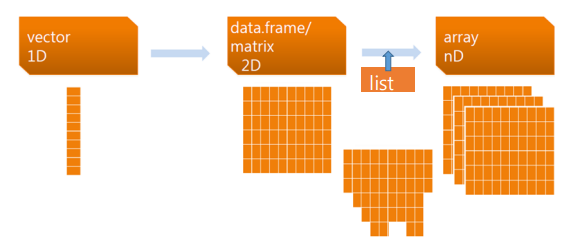
2.2: Data frame
열내 동질적(국어 점수는 int, 이름은 str) 열간 이질적(국어, 수학, 영어 등) 데이터를 어떻게 저장하는가 따라서 (열, 행) 처리 속도가 달라짐 (ex : 국어 평균 (일열로 하면 점프해서 평균인데, 국어끼리 모아두면 걍 찾지 않고 평균 낼 수 있음)) - 밑에 (데이터를 ``으로 저장)-
행우선 : 행에는 이름, 열에는 속성(특성) => 행으로 저장 (검색)
열우선 : 데이터 평균 내기 위해 (5배 이상 빨라짐) (통계)
결측치(하나라도 데이터가 빠지는 것)이 있으면 안됨 (하나가 null -> 모든게 null 나옴)
2-3: List
but 없는 것(사각형이 아닌것)도 담을 수 있는 것이 list (이중적도 저장 가능, 서로 다른 것들)
2-4: Array
2개 이상 (그냥 데이터가 담아져 있을 때) 주로 이미지 (행열 연산 아닐 때) (2,3차원..)
2-5: Matrix
전체 데이터가 동질적(숫자 or 문자) : 2차원
=> 행렬 곱 연산 : 특징을 추출 : 내적 연산의 연속
=> 앞 행과 뒤 열 수가 일치해야 함
3. R 설치
자 이제 R을 설치하고 실행해 보도록 하자
Step1. java 설치
R을 사용하다 보면 java가 필요한 경우가 있어 Java Downloads | Oracle에서 각 환경에 맞는 파일을 다운 받아줍니다. 이때 오라클 계정이 없으면 회원 가입을 하고 진행합니다.
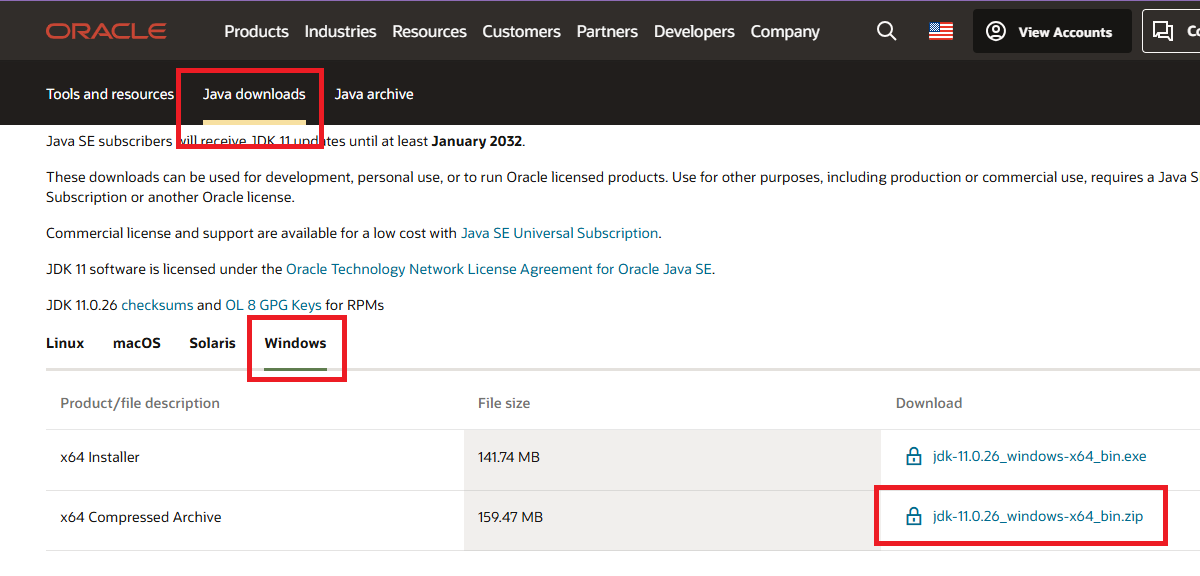
java 다운로드
압축을 풀어주고, 제어판 -> 시스템 -> 고급 시스템 속성 -> 환경변수를 눌러 줍니다.
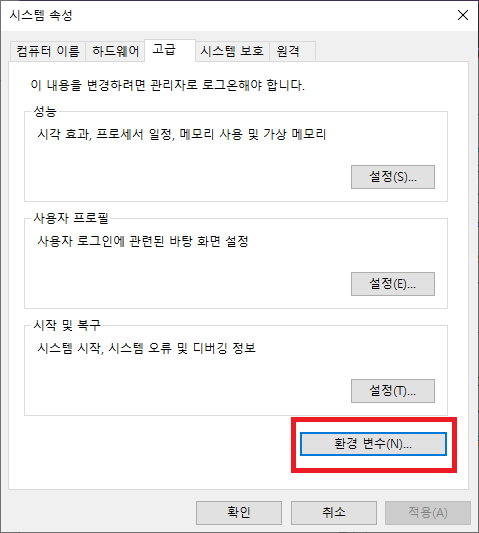
환경변수
새 시스템 변수를 다음과 같이 입력합니다. 변수 이름은 JAVA_HOME이고 이때 변수 값은 각자 압축 푼 파일의 위치입니다.
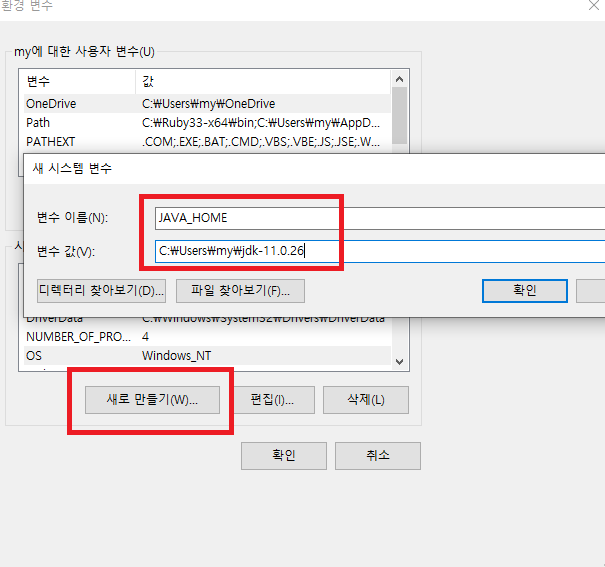
새 시스템 변수 만들기
path를 선택하고 편집을 눌러 뜬 창에 새로 만들기를 선택하고 %JAVA_HOME%\bin를 입력하고 확인을 다 눌러줍니다.
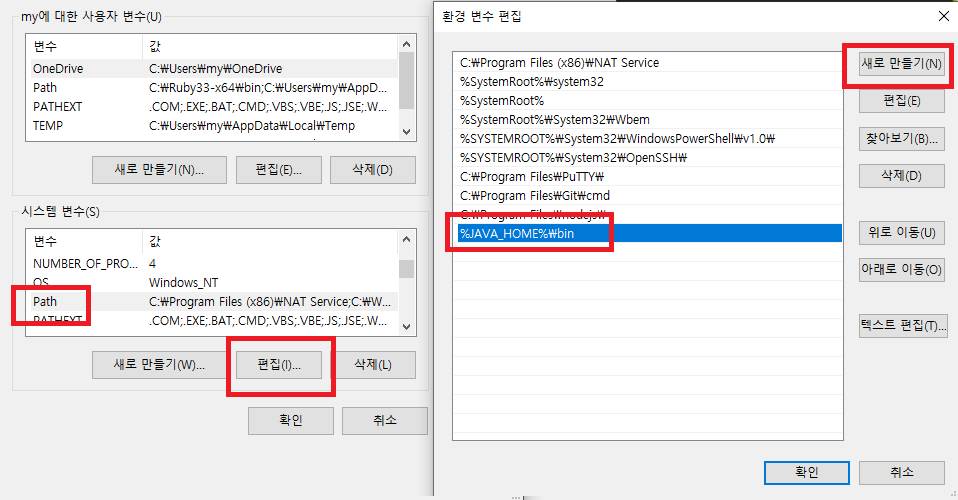
path
cmd에서
Java --version 을 입력해 설치가 잘 되었는지 확인합니다.

설치 확인
각자 환경에 맞는 R과 R Studio를 별다른 변경 사항 없이 디폴트로 설치해줍니다. 링크는 여기를 클릭해 주세요.
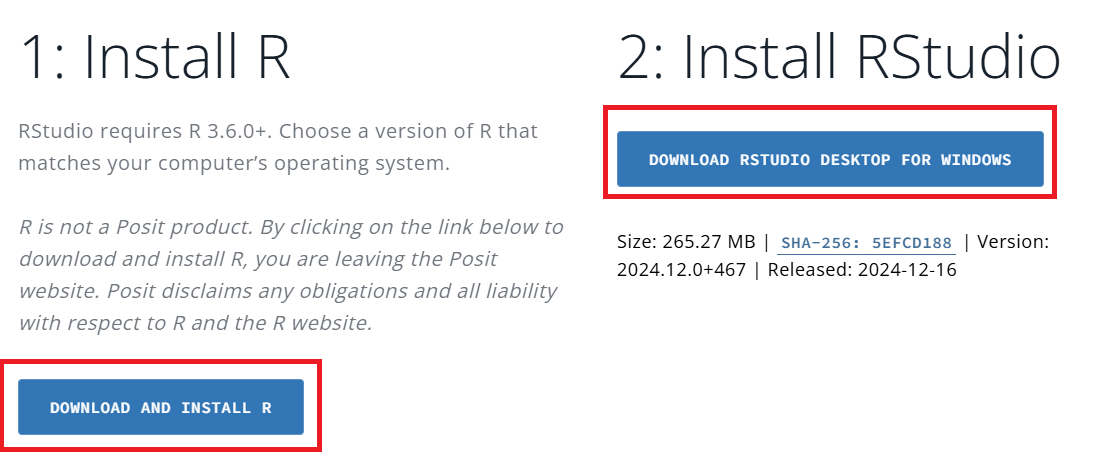
R, R Studio 설치
4. R 간단한 예제
이제 간단한 R 사용법에 대해서 설명하겠습니다. 기초적인 내용이라도 한번 직접 실행해 보는 것을 추천 드립니다.
R Studio를 실행시켜주고 따라 쳐보시길 바랍니다. ctrl + Enter를 하면 수식이 적용됩니다. 값을 바로 확인하고 싶은면 괄호()를 쳐주시면 됩니다.
입력 방식
(x <- 5) # 변수 지정 x typeof(x) # R은 자동으로 데이터 타입 할당합니다 => double x = as.integer(x) # integer로 변환 typeof(x) y <- x # 주소를 전달 typeof(y) x <- 10 # 주소가 변경 y # y는 값이 바뀌지 않습니다. z = "대한민국" print(z) cat(z) 연산자
x+y x-y x*y y/x y%/%x # 몫 연산자 y%%x # 나머지 연산자 y^x #거듭제곱 연산자 자동 형변환
t<-1.23 # double(8바이트) - 더 넓은 범위 표현 / int : 4바이트 x+t s=1.01 x+s typeof(x) typeof(t) 관계연산자
x <- 5 y <- 16 x<y x>y x<=5 y>=20 y == 16 x != 5 # 부정 vector ( combine ) : 데이터 타입이 동질적
사용법은 배열과 동일 x <- c(TRUE,FALSE,0,6) # 숫자, 문자 동시에 들어갈 때 타입을 확인해 보자 typeof(x) mode(x) class(x) (y <- c(FALSE,TRUE,FALSE,TRUE)) x+1 # for문이 없는 벡터화 연산 x <- x+1 # R은 가능한 원본을 보호하도록 작성 x !x !y x&y #논리 and : 요소별로 판단 x && y # 맨 처음 요소만 판단 x|y # or 벡터 만드는 방법 ( range, 맨 뒤의 수를 포함)
v <- 2:8 print(v) % % 연산자를 만드는 방법
t<-1:10 v1<-8 v2<-12 v1 %in% t #포함연산자 print(v1 %in% t) print(v2 %in% t) 행렬 ( 2행 3열 )
#c로 vector 형성, 행2개, 열3개, byrow -> 행우선 (M = matrix( c(2,6,5,1,10,4), nrow = 2,ncol = 3,byrow = TRUE)) (M = matrix( c(2,6,5,1,10,4), nrow = 2,ncol = 3,byrow = FALSE)) t(M) # 전치행렬 : 행과 열을 전치 t = M %*% t(M) # 2 by 3 * 3 by 2, %*% : 행렬곱연산자 print(t) # %*% : 앞에 있는 열수와 뒤에 있는 행수가 일치해야 가능 # = > 내적 2*2+6*6+5*5, 2*1+6*10+5*4 # 1*2+10*6+4*5, 1*1+10*100+4*4 recycling
c(1,3,5,7,9) * 2 c(1,3,5,7,9) * c(2,4) c(1,3,5,7,9,10) * c(2,4) c(2,4) * c(1,3,5,7,9,10) (data = 1:5) factorial(1:5) factorial(data) 매개변수로 기본이 벡터가 전달
(e의 지수형) exp(1) exp(2) exp(2:10) cos(c(0, pi/4)) sqrt(c(1,4,9,16)) sum(1:10) exp(0.1*10) # 이자율 * 10년 : 복리계산 결측치
sum(c(1,2,NA,3)) 1 / 0 0 / 0 Inf / NaN # 무한대, not a number Inf / Inf log(Inf) Inf + NA 사용자 정의 연산자
`%divisible%` <- function(x,y) # 함수도 객체 { if (x%%y ==0) return (TRUE) else return (FALSE) } 10 %divisible% 3 10 %divisible% 2 `%divisible%`(10,5) 통계학
#기술통계 대표값으로 데이터를 보는 이유 : 복잡 -> 단순, 비교 가능 #질적요소 : 분산(차의 제곱), 표준편차(sqrt) score <- c(85,95,75,65) score mean(score) sum(score) var(score) # 분산 sd(score) # 표준편차 sum((score-80)^2)/3 # 자유도 = n-1 sqrt(sum((score-80)^2)/3) R에서 오버로딩이 불필요함
#함수 이름은 같지만 데이터타입이 다르거나 (데이터 타입 지정하지 않음) #매개변수의 갯수가 다르면 다른 함수로 인식 (default 매개 변수) score<-c(85,95,NA,75,65) score sum(score) # => na.rm = F가 숨어 있는 것임 mean(score, na.rm = TRUE) # rm : remove sum(score, na.rm = T) 데이터 타입
x <- c(10,20,30,'40') # 문자로 바뀜 (더 넓은 범위) mode(x) typeof(x) 형변환 (as.~)
(xx <- as.numeric(x)) mode(xx) 범주형 데이터
gender <- c('M','F','M','F','M') gender # 문자열 mode(gender); class(gender) plot(gender) fgender <- as.factor(gender) #형변환 (범주형) fgender # 종류 : F M fgender[3] levels(fgender) plot(fgender) 날짜
Sys.Date() Sys.time() today <- '2025-01-20 15:43:04' today mode(today) # character today2 <- as.Date(today) today2 mode(today2) # numeric ctoday <- strptime(today, '%Y-%m%-%d %H:%M:%S') ctoday class(ctoday) 함수 확인하기
help("mean") ?sum args(sum) example(sum) indexing
a = c(1,2,3) a[2] b = 2:10 b[2] b[c(2,3,4)] x<-c(1:9) x x[3] x[c(2,4)] x[-1] # 제외하고 x[c(2, -4)] # +, - 혼용하면 안됨 x[c(2.4, 3.54)] # 소수를 정수화 (내림) x[c(TRUE, FALSE, FALSE, TRUE)] # Boolean indexing, (1(t), 2~3(f), 4~5(t)...) x[x<3] x[x>3] R은 열로 저장
x <- c(1,5,4,9,0) length(x) # 전체 데이터 개수 NROW(x) # 행수 NCOL(x) # 열 수 Range 추가 내용
seq(1, 3.2, by=0.2) # 초기, 한계, 증가 seq(1, 5, length.out=4) # 출력개수 seq(1, 6, length.out=4) #문제 3.2에서 1사이의 값을 0.2 간격의로 출력
seq(3.2, 1, by=-0.2) 반복 (b<-rep(1:4,2)) (d<-rep(1:3, each=3)) (d<-rep(1:3,2, each=3)) # 각각이 먼저 실행 문제
#1) Vector1 벡터 변수를 만들고, “R” 문자가 5회 반복되도록 하시오.
#2) Vector2 벡터 변수에 1~20까지 3간격으로 연속된 정수를 만드시오.
#3) Vector3에는 1~10까지 3간격으로 연속된 정수가 3회 반복되도록 만드시오.
#4) Vector4에는 Vector2~Vector3가 모두 포함되는 벡터를 만드시오.
#5) 25~ -15까지 5간격으로 벡터 생성- seq()함수 이용